The data gateway - some thoughts…
The image you see here is from the “Powerhouse Museum Collection”, part of the Flikr Commons Collection, entitled :
Sir Malcolm Campbell at the wheel of the “Bluebird”, with crowd, 1926 - 1936
I chose this image because it shows a work in progress, a community, and a beast of a machine. The data gateway finds itself perhaps far, far way from being a beast of a service, but it certainly is a work in progress and shows a lot of potential for communities reliant on data-intensive science.
In previous posts, I discussed our work on developing a gateway which could provide the functioanality that the H3ABioNet project needed to ingest data into a staging area easily, from collaborators around the world. We discussed various options, front-end user tools, web interfaces, back-end and CLI tools, etc
What I tried to impress on the readers was that while there are many, many ways to skin this cat, some ways are more appropriate than others. There is a general tendency in research activities to do it yourself - to consider the problem at hand and hack together, with just the right amount of effort (and pain) a set of tools which (let’s face it) kinda does the job. This is particularly true for individuals, where web-based free or freemium services like Dropbox, Google Apps, Globus Online1.
When the collaboration grows beyond a certain size2, however, unless a common set of tools is decided on, it can quickly fragment. Furthermore, certain services are so general that there’s no point in each developing their own implementation of it, but it makes more sense to adopt a common implementation offered by a third-party. Like roads, schools, police and so on, in order to scale, it makes more sense for the common good to delegate the responsibility for services like identity provision, network provision, resource publication, etc to trusted third parties. In the case of public infrastructure, this is usually the government3; in the case of digital science, this is e-Infrastructure.
Just to drive home a point (and apologies in advance for harping on), these rely fundamentally on standards, which I’ll get into a bit later in this post. Interestingly, the recent e-IRG recommendations suggest that it is the responsibility of the user communities to contribute to the development of these standards4 :
International user communities requiring e-Infrastructure services should organize themselves to be able to address the challenges in their future roles:
- Driving the long term strategy for their e-Infrastructure needs
- Using their purchasing power to stimulate the development of suitable, effective e-Infrastructure services;
- Participating in the innovation of e-Infrastructure services;
- Contributing to standards.
Some clarification - what is the Data Gateway ?
SAGrid is in the business of standards-compliant e-Infrastructures. There’s a very thin line between getting stuff done and getting stuff done right, and often the latter is either impossible at the time, or takes far too much effort. Wherever possible, we try to develop services which implement standards, and so are easily interoperable with peer infrastructures or other services. To quote the ITU5 :
“Open Standards” are standards made available to the general public and are developed (or approved) and maintained via a collaborative and consensus driven process. “Open Standards” facilitate interoperability and data exchange among different products or services and are intended for widespread adoption.
So, why this long digression on The Way Things Should Be™ ? Well, let’s take a closer look at the Data Gateway implementation. What you may have been thinking of as “the data gateweay” -
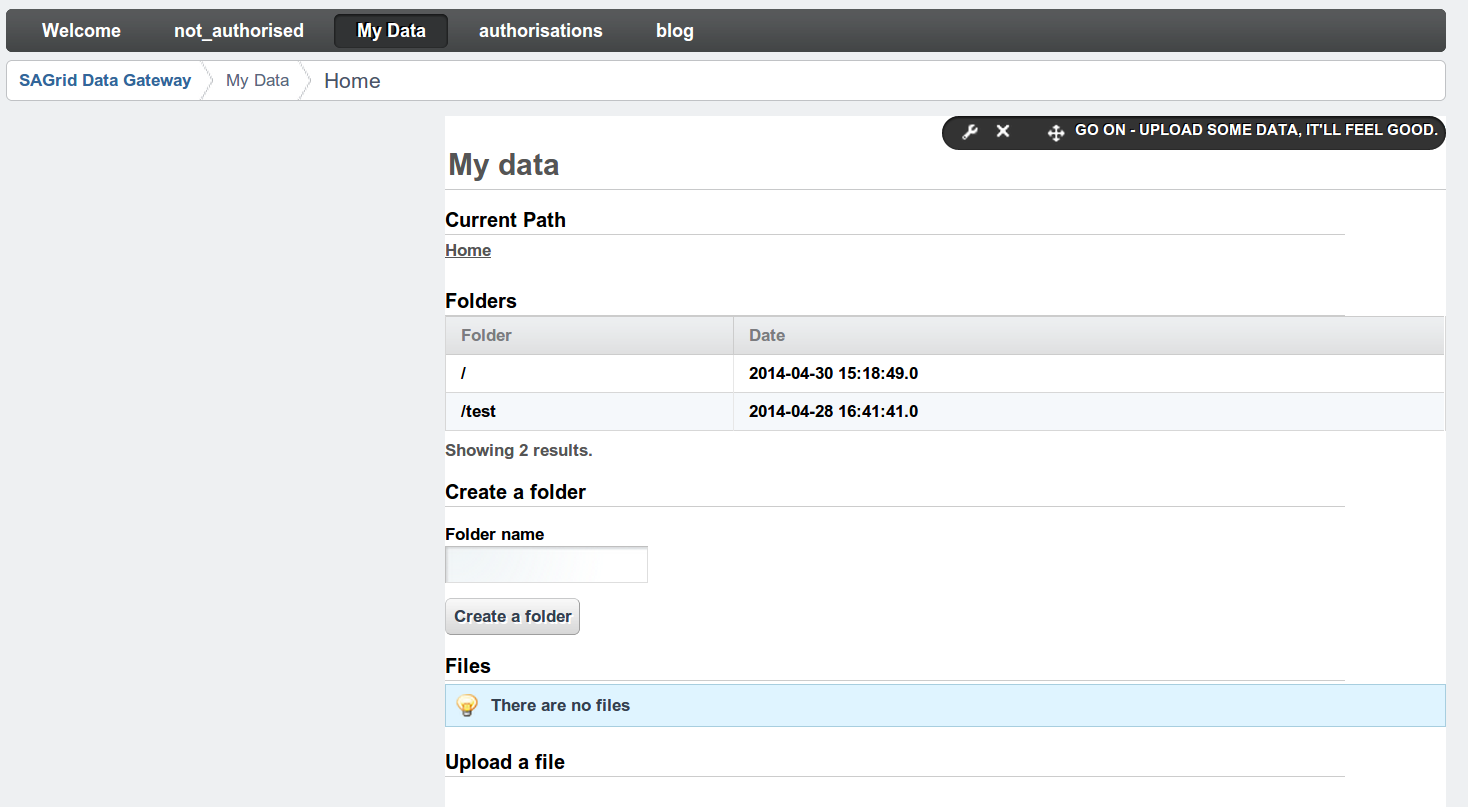
is actually just a portlet which was hacked together to show what the gateway can do. The Data Gateway6 actually implements a full API through which a developer can build portlets to store, move and retrieve data from arbitrary storage resources, in principle. This is done using judicious use of standards-compliant and Liferay-specific technologies. Interaction with remote and local storage is taken care of with SAGA (in the former) and native Java (in the latter) calls; grid resource discovery is done using calls to the authoritative source of information, the GOCDB, and through parsing GLUE Schema7.
In the implementation of the grid storage API for example, you only see a bunch of
import org.ogf.saga
There are no special libraries for this storage type or that, just one implementation; SAGA takes care of the rest. You can imagine how this makes life easier for the portlet developer. The security context is provided by VOMS which is an OGF standard8 widely used in distributed, collaborative environments; it also extends the X.5099 standard. Resources are discovered through standard information provider means, as mentioned above.
A closer look
To clarify this, here’s how the storage resources are discovered10
if(resourceRequest.getResourceID().equals("gLite")){
if(ParamUtil.getString(resourceRequest, "action","getVOResources").equals("getVOResources")){
URL proxy= new URL(ParamUtil.getString(resourceRequest, "proxy"));
InformationUtil iu= new InformationUtil(proxy, getInitParameter("GOCDB_TBDII"));
The GOCDB_TBDII and some other global configuration variables are specified in files internal to the gateway :
import it.infn.ct.einfrsrv.sb.service.PropertiesLocalServiceUtil;
import it.infn.ct.einfrsrv.util.LocalPropertiesKeys;
import it.infn.ct.einfrsrv.util.eInfraPropertiesKeys;
import it.infn.ct.einfrsrv.util.gLitePropertiesKeys;
… the code then continues:
resourceResponse.setContentType("application/json");
JSONObject json = JSONFactoryUtil.createJSONObject();
PortletSession session= resourceRequest.getPortletSession();
try {
json.put("voName", iu.getVOName());
session.setAttribute("voName", iu.getVOName());
JSONArray tvobdii= JSONFactoryUtil.createJSONArray();
for(String tb: iu.getVOTopBDII()){
tvobdii.put(tb);
}
You can see here that the portlet is dealt a JSON array of top-BDII’s which support the VO in question …
json.put("VOTopBDII", tvobdii);
session.setAttribute("VOTopBDII", iu.getVOTopBDII());
JSONArray vose= JSONFactoryUtil.createJSONArray();
for(SE se: iu.getVOSE()){
vose.put(se.getHost());
}
… which is then parsed to retrieve a list of storage hosts. One of these is selected as the default, which the portlets using the API are referred to.
So, the Data Gateway provides the portlet developer a means to access arbitrary storage; the way it’s presented to the user depends entirely on the portlet in use. This could be such a bare-bones portlet as the one current users are seeing, which only allows upload and download, or it could be a feature-rich portlet which allows both new functionality (replication, sharing, etc) as well as more information given to the user.
Initial anecdotal results
I’ve run a few tests on the gateway to see how stable and performant it is. So far, it hasn’t experienced a catastrophic failure for file sizes below the size of the virtual disk assigned to the VM11.
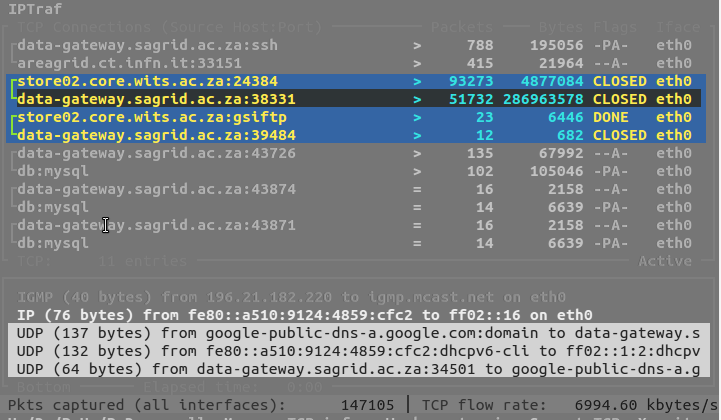

Some uploads were made from my laptop using files of various sizes12, from an eduroam wireless access point. This was not what one could call a “high-performance” network, but was certainly better than most of what our collaborators on the continent will experience. Let’s just say the bottleneck was the originating network and not the data gateway.
The overal experience was very encouraging; there are two numbers you can take away from this brief experience :
- 10 min / GB for upload from the internet
- 2.5 min / GB staging to data storage on SANREN
For a 50 GB transfer, such as the one that is planned between the group of Mary Claire King at the Genome Sciences Department of the University of Washington School of Medicine, we can probably expect the transfer to take about 8 hours. That’s pretty sweet, if you ask me.
On the downside, I’m informed by collaborators in Tunisia that the gateway is giving them timeouts and errors13 - so the user experience is far from unique at this point. The point of these blog posts is about teasing out the finer details and making things better…
Data Gateway - Quo Vadis ?
So, given how apparently great the data gateway is, it’s time to think about exploiting it better. This entails some added functionality, and perhaps tweaks in the design and internal algorithms. Everything starts, however with a wishlist. Here we go…
Provide more verbosity to the portal admin and user
The portlet currently does things very, very quietly. Neither the portal administrator which configures the portlet nor the user which interacts with the portlet is told anything about what’s going on in the background. The developers have touted this as a feature in that the portlet just works (without being all braggy about it) and indeed when in production, you’d want to reveal as little of what is happening in the background as necessary. However, it would be wise to tell at least the portal admin what’s going on. For example
- I’m connected to the GOCDB (or not)
- I’ve found the following top-bdiis which support your VO
- I’m pruning the list based on which of them are duplicates
To the user, you want to subtly modify and guide their behaviour based on the state of the gateway. I’ve pointed out before that the design of the gateway as it stands makes it a bottleneck. You would like to moderate user behaviour to avoid breaking the gateway, and receiving irate mails from users complaining that “nothing you do ever works !”
It would be very useful for example to keep track of the performance of the gateway and summarise this in the portlet, in order to pre-empt user questions like :
- what bandwidth am I getting ?
- what bandwidth can I expect ?
- why is my speed lower than previous attempts ?
If there are several concurrent transfers, one can expect differences in performance14 depending on the state of the network congestion or usage of the portal. It would be useful to for the user to know what to expect, either through simple heuristics (expected_bandwidth = max_bandwidth / number_of_active_users) or through some adaptive prediction.
Data can be visualised with something like jFreeChart15, provided it is generated and collected properly.
Integration with SF.net/Github or RT to open issues or feedback
When things do go wrong, or there are legitimate feature requests, you want to both give the impression to the user that their issue has been taken account of, as well as avoid being overwhelmed with hard-to-manage email threads. We also want to separate design issues from interface issues. It would be nice to have two simple buttons in the portlet that :
- Make a new feature request to the portal admins
- report a bug or error to the developers
In the first case, a form could be presented which sends an email to an RT queue. In the second, the user could be redirected to the github or sourceforge page where the code is hosted.
These are of course general improvements to any kind of project under development, and should be implemented in a general way using whatever Liferay can provide.
Liferay session expires.
This is a pretty minor issue, but can potentially be extremely frustrating. Liferay has a default session timeout for the portal as a whole, meaning that if no activity is detected after this timeout the session will expire. This is a very common feature of web pages, so I’m not surprised that Liferay has this as well. The issue of course is that you’re doing large data transfers which are going to take very long (on the order of a few hours). The last thing you want happening is a transfer failing because your session has timed out16.
Of course, you could set the default timeout to be very long, or you could set the timeout of only the data transfer portlet to be very long17. Apparently, though, this is not possible :
“Long story short, no you cannot have individual portlet timeout values that have any true meaning in the portal.”
So, what we could think about doing then is to have the portlet keep the session alive itself, while transfers are ongoing. This would require re-implementing session.js, probably, to listen to the portlet itself and decide when it was finished to start the timeout counter. I’ll leave this one to the Liferay experts !
Release the user’s session while the file is staged to the grid
The upload of data to grid storage consists of a two-stage process; first move the data to the portal, then move the data from the portal to the grid. Presumably this will be the case for cloud storage as well. Currently, the workflow of the portlet is serial and doesn’t release the session back to the user; even though the transfer from the user’s location has finished (something which the user is not informed of, by the way), they still have to wait until the staging to the grid is finished before they can upload another file or even leave the page.
It would be good to have an asynchronous staging of the files to the grid once the connection from the user’s location is closed.
Put the web traffic and the grid traffic on two separate interfaces
It came to my mind while testing this service last week and watching the network transfers to see what kind of performance we are getting, that there is some incongruency in the design of the Gateway. The data flow is asymmetric, in that it should flow in one direction - from “the internet” to “the grid”18. This is schematically shown in the figure below.
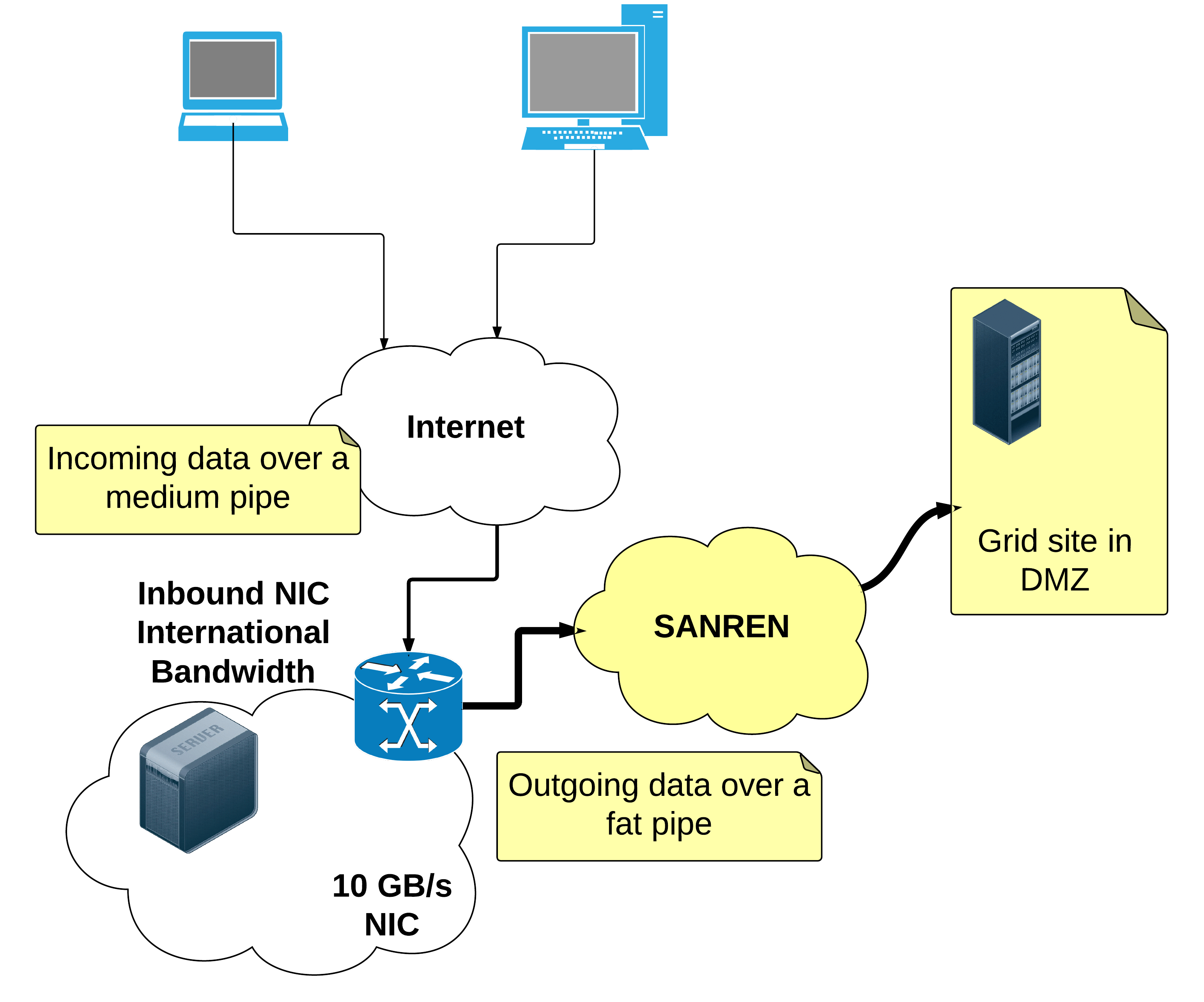
Implementing this would probably make the site network admins happy, as well as improve user experience significantly during congested periods.
Scheduled stage
Another way to make more efficient usage of the available bandwidth is to predict when the network will be less congested and schedule large data transfers for that time. This would involve some kind of cron on the host, which Liferay interacts with to schedule actions. I haven’t looked too deeply into this, but it seems like you’d have to code that bit yourself19.
Another way to do this, perhaps the Right Way ™ would be to use the FTS to schedule transfers. This would of course require a lot of coding, but the FTS in use could be discovered from the GOCDB in the same way that the top-BDIIs and Storage Elements are. There would likely be little need for a UI within Liferay, since the FTS provides it’s own web interface
Upload from URL
Simple - instead of pointing the gateway at a file to upload, point it to a URL. A publically available URL of course ! This will be a pull action, and depending on the webserver on the other side, your performance could be drastically different. What’s for sure is that this would be an intrinsically asynchronous action and would allow the user to go off and do their own thing while the data was being moved. Again, to avoid overloading a single site - ZA-UFS, which is hosting the data gateway - the transfer should be initiated directly from the final storage point, instead of being staged first to the data gateway.
Mockup of various types of portlets
So, finally, here’s what I think the portlet should look like :
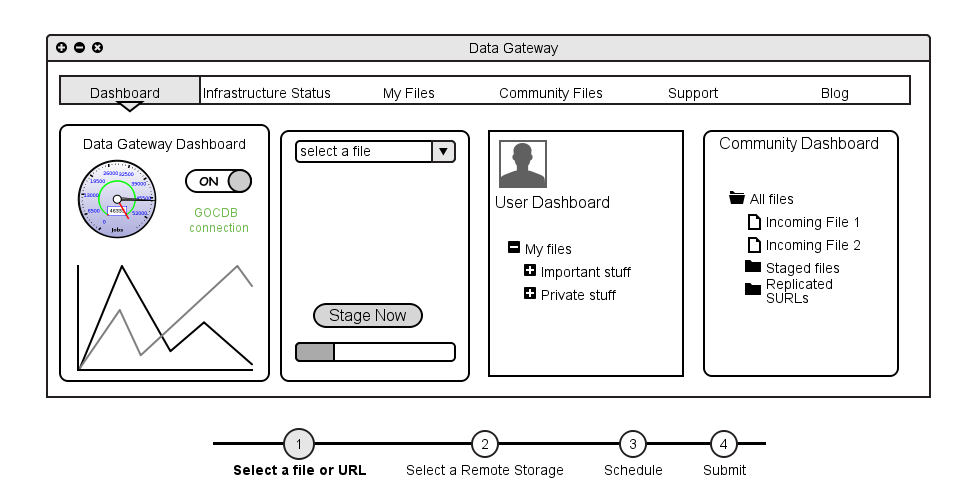
The user would see far more contextual information than just what appears to be a virtual filesystem. Firstly, there would be a simple summary of what state the data gateway is in. The second part of the portlet would be what we now have as the simple input, except that it would allow passing the data gateway a URL as well as a local file. Thirdly, there would be a user dashboard which we currently have, showing the user their own private information. Secondly, there would be a “sharing” dashboard for the community, showing all files belonging to that community. This would likely be curated by a different role than the simple user, for which we’d have to tweak the permissions of the portlet, but this is well supported by Liferay. Finally, there would be the possibility to expose the SURLs of the files that the gateway is managing, so that if need be users could access them in some other way.
I’ve also imagined a slight modification to the upload procedure where instead of having a simple one-step workflow, two additional steps would be added :
- Select a remote storage would allow users to select from a predefined list of storage elements (perhaps using one that’s closest to them)
- Schedule would provide a preferred time (or deadline) to the portal, allowing it to pass this information on to the FTS or it’s own internal scheduling system in order to optimise transfers.
There are also some additional bits which I’ve discussed above linked from the nav bar - these would be simple to add and configure.
Summary and Conclusions
The data gateway has a long way to go. Initial tests show that with the right configuration it can be very stable for file transfers exceeding several GB. Some minor architectural changes to the portlet would take greater advantage of the underlying API, while using additional grid or cloud services would provide a far more responsive and scalable service to user communities.
Input is requested specifically from the focus community (H3Africa), but we welcome comments from any and all users who want to help us develop this service for the wider user communities.
Acknowledgements
I’d like to thank the main developers Marco Fargetta and Riccardo Rotondo for their continued feedback and support while evaluating this service. The resources for the service are made available by the University of the Free State HPC centre, a member of the South African National Grid.
This work is partially supported by the CHAIN-REDS project and undertaken for SANREN with support of the South African Government Department of Science and Technology
Footnotes and References
-
Yes, I’m comparing Globus online to Dropbox, for two reasons - one with a positive connotation and one with a negative connotation. On the positive side, it’s a black box, which is designed to just work; user authenticates, sets up transfer endpoints and proxies and shifts data. However, it’s not an infrastructure - you have to do all the collaboration stuff yourself. There’s no concept of VO, there’s no trust anchor, you can’t discover endpoints (apart from searching what people have already put in), there’s no authoritative source of information regarding services. ↩
-
This is a perfect place for citation needed ! I have only anecdotal evidence, and perhaps there’s no actual reason for this. Indeed, I’m starting to think that there’s some kind of complicit conspiracy between who-knows-who, some kind of post-communist, socialist plot to get us to accept that we need to share resources and that these need to be developed and operated by some kind of tech illuminati. Hey, it’s a public holiday, I’m allowed to rant. ↩
-
Your mileage may vary significantly - remember, this is a personal blog, I’m allowed my opinion (in South Africa at least). Section 16 states “Everyone has the right to freedom of expression, which includes freedom of the press and other media; freedom to receive or impart information or ideas; freedom of artistic creativity; and academic freedom and freedom of scientific research.” ↩
-
See http://www.e-irg.eu/publications/e-irg-recommendations.html ↩
-
The International Telecoms Union defintion of Open Standards : http://www.itu.int/en/ITU-T/ipr/Pages/open.aspx ↩
-
More accurately, the e-Infrastructure Service of the Catania Science Gateways project. ↩
-
S. Andreozzi, S. Burke, L. Field, G. Galang, B. Konya, M. Litmaath, P. Millar, J. P. Navarro, “GLUE Specification v. 2.0”, http://www.ogf.org/documents/GFD.147.pdf ↩
-
V. Ciaschini, V. Venturi, A. Ceccanti, “The VOMS Attribute Certificate Format”, OGF GFD.182 ↩
-
Cooper, D., Santesson, S., Farrell, S., Boeyen, S., Housley, R., and W. Polk, “Internet X.509 Public Key Infrastructure Certificate and Certificate Revocation List (CRL) Profile”, RFC 5280, May 2008. ↩
-
Direct link to the source : https://sourceforge.net/p/ctsciencegtwys/einfsrv/sources/HEAD/tree/trunk/einfrsrv-portlet/docroot/WEB-INF/src/it/infn/ct/einfrsrv/management/eInfraServPortlet.java#l434 ↩
-
I haven’t had the cajones to try files bigger than that, but I suspect that this action will simply kill the jvm and the actual vm. ↩
-
A sequence of files in steps of 1 GB were created from 1 GB to 25 GB. No performance change in average bandwidth was noticed. There might be some impact of overhead for significantly smaller files. ↩
-
Reported on Friday May 2. Can’t see anything relevant in the logs and I can’t reproduce the error. My first guess is that this is a Liferay timeout issue, although it could likely be an AuthN issue. Boh… ↩
-
This is especially true given that the portal is currently running on an albeit beefy VM. ↩
-
Charts - a short digression. Call me biased, but I love the way that ALICE visualises the status and usage of its infrastructure. The ALICE monitor shows the user in great detail what’s going on. Using jFreeCharts they allow a lot of data dynamically visualised data. Clearly, that data has to be be collected or generated somehow - a task which is probably better left to a dedicated machine, say
data-monitor.sagrid.ac.za. A lot of the data necessary to plot performance of the data gateway should come from network monitors, perfSONAR results, etc. At the end of the day, the gateway is just that - a gateway to an infrastructure, not part of it. The infrastructure should be monitoring itself. ↩ -
This is one of the things that Globus Online does exceptionally well of course. ↩
-
It seems this was requested by a few people in the Liferay community. The quote comes from http://www.liferay.com/community/forums/-/message_boards/message/21600002 ↩
-
By this, I mean “From undertermined, random sources to predetermined, well-known destinations”. This is a concept which is somewhat inherent in the gateway; it’s very name implies some sort of boundary. ↩
-
A very quick search only showed http://www.apoorvaprakash.in/2011/02/liferay-scheduler.html. Maybe the Liferay Ajax support in Allow wil allow that… ↩