TL;DR We made a style guide - this is how it works in practice.
A few weeks ago, I announced a style guide for developing Ansible roles. The intended audience is the developers of middleware components1 and the aim of the guide is to improve or ability to collaborate, and to deliver products smoothly and reliably, without breaking the infrastructure in general.
A typical case would be an existing product which performs some specific function e.g., a storage management front-end service. Another case would be the one I want to use as an example here - the so-called “worker-node” function.
Case: Worker Node
The worker node is essentially a composition of clients which interact with infrastructure components:
- “validate user token”
- “get data”
- “submit workload request to your local resource manager”
- “check how that’s going”
- “send accounting data”
etc. If we were starting out now, these functions might well be built as serverless endpoints, but as with all things infrastructure-related, one has to deal with the legacy of what came before.
The worker node function has typically been distributed as a meta-package in OS repositories - an RPM or DEB which expresses all of the necessary dependencies. A site wishing to provide the worker node function could therefore easily ensure that this was present by simply installing the metapackage. That is, if the prerequisite state is assured.
That’s a big if and a big ask in 2018.
Building the worker node now
If we had the case of a totally new site in the federation wishing to participate by offering compute resources, we would probably want this site to be integrated and functional with a little demand on the site itself. If we start from this position, we might well consider the site resources and the layer of middleware necessary to federate it as separated by a well-defined contract : We (federation) give you a bunch of endpoints to send data to, you (resource provider) send the data. We’ll go one step further and provide you with the functions which send that data, so that you have zero interference with your setup.
This separation of function from platform is why containers were developed.
Modelling services
How would things be different, if we approached this from a 12 factor point of view? We have to deal not only with the installation of binaries and other files, but also the configuration of these, around site-specific setups, procedures and policies. The last thing a product team wants to deliver to an endpoint which will eventually use it, is a product which doesn’t play nicely with the rest of the environment. This could include, for example, hard-coding certain paths, asserting the presence of particular users or, usage of the network in a specific way. All of these would be examples of “bad behaviour”, since the integration of the site into the federation is not done according to a central prescription, but according to an OLA agreed to by both parties.
We therefore need to deliver not only products, but also strategies for deploying those products, which are flexible enough to respect local site policies. If we are to be fluid, we also need a high degree of trust that the final result will not only perform as advertised (i.e., works, and does what it needs to do), but also won’t break local setups. The Ansible Style Guide describes aspects of developing, testing, documenting and delivering the role. It is more about how than what, because the overriding, big-picture goal is to solve problems and have them stay solved.
The way to do this is, as with most engineering problems, to factor out the big problem into smaller ones in some logical way. Doing things in this way, we come to have a sort of “dependency tree” of roles, so that infrastructure engineers can separate problems and solve them permanently.
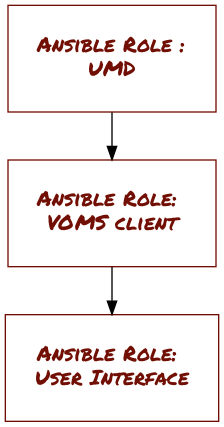
This has the happy consequence however that end users (typically, site administrators) can re-use these products with confidence at their site, know where to go for support and understand how to contribute back. Looking at the simple case of building a User Interface, shown in Figure 1, this is quite easy to understand. We can even link the roles themselves to various actions and outputs as shown in Figure 2.
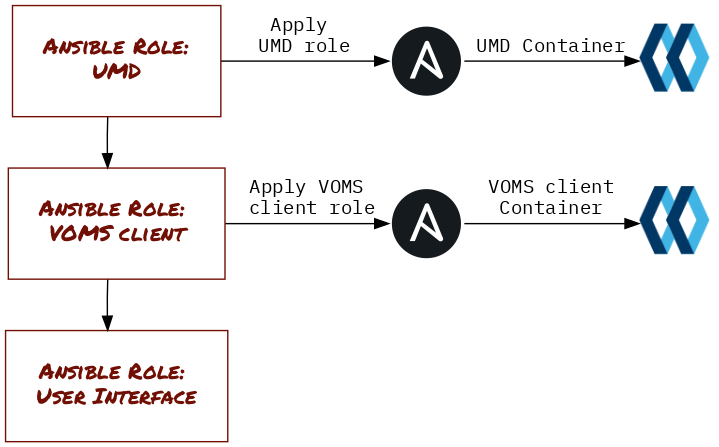
In this way, we can continue modelling individual roles and map events in source code to artifacts in production. The final touches to our modelling flow are added in Figure 3, where we add the links to the respective GitHub repositories and the all-important testing phase - more on that in a later section.
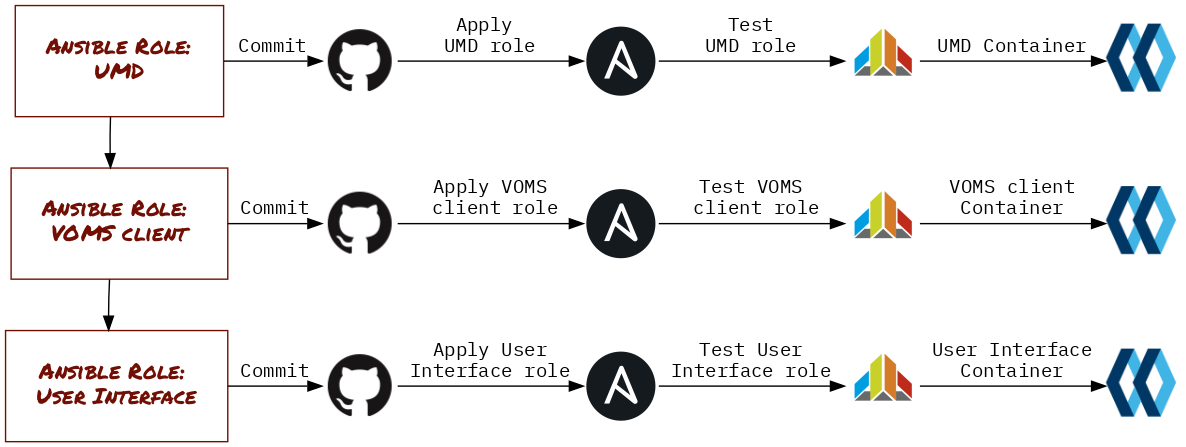
Action
Now that we have a clear idea of how to go about modelling our roles, and putting the tools in place for our continuous integration and delivery pipeline, we can take a closer look at using the EGI Ansible Style Guide to get started.
Getting started
The first thing you need to do is get the style guide, and use it to create a new Ansible role. Ansible roles are usually generated with the Ansible Galaxy CLI command init, but this uses a role skeleton which doesn’t cover many of EGI’s bases.
We therefore use the egi-galaxy-template in the Style Guide repo to generate a better one:
git clone https://github.com/EGI-Foundation/ansible-style-guide
ansible-galaxy init --role-skeleton=ansible-style-guide/egi-galaxy-template ansible-role-wn`
We now have a shiny new Ansible role : ansible-role-wn.
Before we go about implementing it, we need to have a means for implementing tests and generating test scenarios.
Typically we use Molecule for this, which is great for generating a full set of test scenarios and strategies.
Install Molecule with pip, and generate a scenario, using a virtualenv^[VEnv]:
$ virtualenv style
$ source style/bin/activate
(style)$ pip install molecule
(style)$ molecule init scenario -r ansible-role-wn
Initial Commit
At this point we have an empty (but stylish) role in a clean environment and a default testing scenario.
Running the test strategy should result in all of it passing2:
molecule lint
molecule dependency
molecule create
molecule converge
molecule verify
This means absolutely nothing, of course - we need to start adding some failing tests !
Tests and Development of Roles
The EGI UMD follows something similar to an Acceptance Test Driven Development pattern.
There are several products, each of which are testing independently upstream by their owners, and candidates for inclusion in the distribution are then communicated to the release co-ordination team. This team then checks whether the UMD Quality Criteria are respected by the product, and whether the new version breaks anything already in production. There are several strategies for doing this, and the one which makes the most sense varies from product to product. Then of course, there is the expected functionality of the product as it would be in production. Finally, there is the consideration that we expect these roles to be deployed into production, which means that the configurations should be hardened and secure by design. Deploying faulty configurations into production environments - even with fully-patched software - can lead to serious degradation in operational security.
We therefore need to implement tests for each of these, as far as we can.
Test-Driven Development3, from Extreme Programming4 suggests that engineering proceed on a “Red, Green, Refactor” cadence.
Red
Considering we are developing the functionality of a worker node here, the first thing we could check for is that the relevant packages are actually present.
Using TestInfra’s package module, we can write this assertion.
def test_packages(host, pkg):
assert host.package(pkg).is_installed
Seems simple, right?
All we need to do is pass the correct fixtures to the function test_packages, to see whether the host we will provision with molecule is in the desired state.
It is important to remember what we are testing for here. We are not testing whether the Ansible playbook has run correctly - or even whether an Ansible playbook has run at all - we are simply making assertions about the host. These assertions should be true no matter how the host arrived at its current state, and of course should reflect the desired state in production environments.
We therefore need to consult the source of truth5 for the worker node package requirements - the same repository that the product team is maintaining which the UMD team has tested and done the QC tests on - to write the fixtures for this test.
We can still converge the role with no problems (nothing has been implemented yet), but when it comes to running the tests (molecule verify), we will be duly informed that they are all failing
Great success. Go ahead and add that test to the scenario:
git add molecule/default/test_packages.py
git commit -m "Added failing test for packages"
git push
Note: using the EGI Ansible Style Guide, there is a .travis.yml already set up for you if you want to do CI on Travis. All you need to do is enable the repository and Travis will take care of the rest.
Green
The next step in TDD is to implement just enough code to make that test pass. With Ansible, this is amost too easy:
First, create a variable in defaults/main.yml to hold the packages that need to be present, taking into account differences across operating systems and OS releases:
---
# defaults/main.yml
packages:
redhat:
'6':
- wn_pkg_1
- wn_pkg_2
'7':
- WN_1
- WN_2
debian:
jessie:
- worker_node
stretch:
- worker_node
Next, add a task which ensures that those packages are present:
---
# tasks/main.yml
- name: Ensure worker node packages are present
package:
name: "{{ item }}"
state: present
loop: "{{ packages[ansible_os_family|lower][ansible_os_distribution_major] }}"
Here, we take advantage of the facts gathered by Ansible identifying the host OS and version - which of course is why we crafted the variable packages in the way we did.
Of course, these tasks need to be applied in an actual playbook. Molecule creates the simplest possible playbook for the scenario for you:
# molecule/default/playbook.yml
---
- name: Converge
hosts: all
roles:
- role: ansible-role-wn
This playbook is used during the converge stage.
If there are any dependencies which are required (which are now clear from our dependency tree!), they can be added before the application of the role you are working on :
# molecule/default/playbook.yml
---
- name: Converge
hosts: all
roles:
- {role: EGI-Foundation.umd, release: 4, tags: "UMD" }
- {role: EGI-Foundation.voms-client, tags: "VOMS" }
- {role: ansible-role-wn, tags: "wn"}
Once we have implemented the functionality, we repeat the converge and verify until the tests are passing.
Refactor, repeat
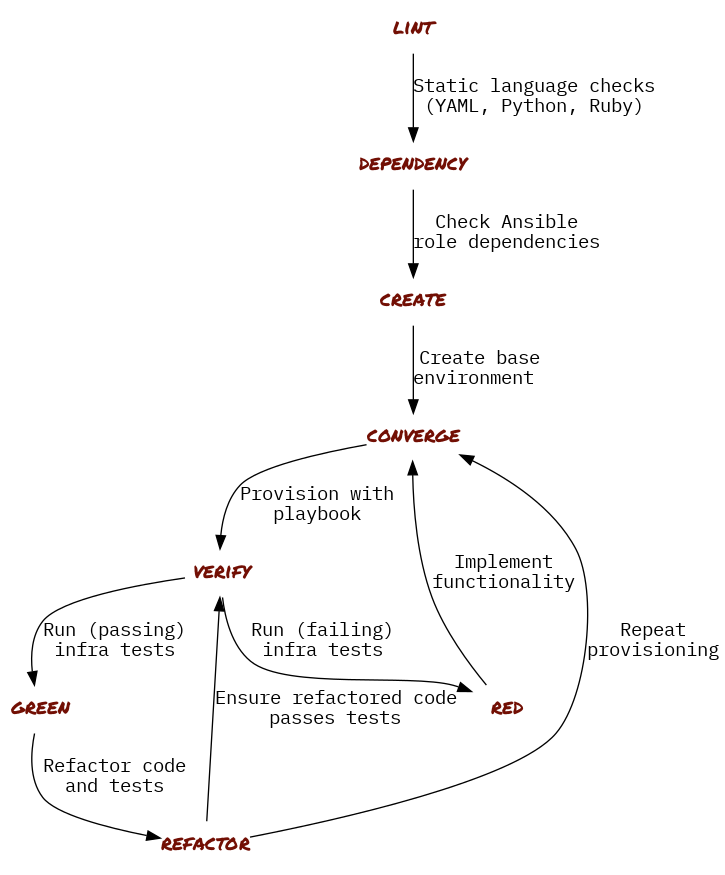
Once the tests are passing, we take another look over our code and tests and try to ascertain whether the tests are really doing what we want them to do and whether that part of the role has been implemented in the best possible way. Figure 4 shows a general workflow of how this should be done.
Conclusions
Clearly, we are not done with the development of the worker node role. However we can be sure that application of this role to any production site will not break the site - a very important point! We now have a solid base from which to step to the next iteration, adding tests for desired behaviour and functionality to achieve it as we go. We also have the means to express this role in arbitrary environments - be they bare metal, hypervisor virtualisation, or Linux containers - all from a single well-maintained role.
As discusssed above The worker node needs to be able to perform many functions - we should try to implement tests for as many of these functions as we can. Similarly, as many of the EGI Quality Criteria should be included in our test coverage, so that we can ensure sites that by applying these roles off-the-shelf, they will be increasing the stability of their site and decreasing their day-to-day operations load.
Furthermore, by using a common style guide for developing these roles, we make it easier to get started for others who want to contribute. The style guide helps peers and collaborators do code review when features or development is proposed via pull request, and gives clear guidelines for how these contributions should be recognised.
All in all, this is a small step towards improving the stability of sites in the EGI federation, without compromising agility and quality, and reducing the friction in the middleware delivery pipeline.
References and Footnotes
-
“Developers of middleware components” is an EGI-federation-specific way of thinking of this audience. What I have in mind is maintainers or product owners who want their products to live in the EOSC ecosystem. Even products which may live at the boundary of this ecosystem may be relevant. ↩
-
This is long-hand for
molecule test, which will execute the full testing strategy. ↩ -
A good overview of test-driven development was written buy Martin Fowler ↩
-
Beck, K., & Andres, C. (2015). Extreme programming explained: Second edition, embrace change. Boston: Addison-Wesley. ↩
-
In this case, it’s the WN Metapackage repository ↩